Overview of Discrete Policy
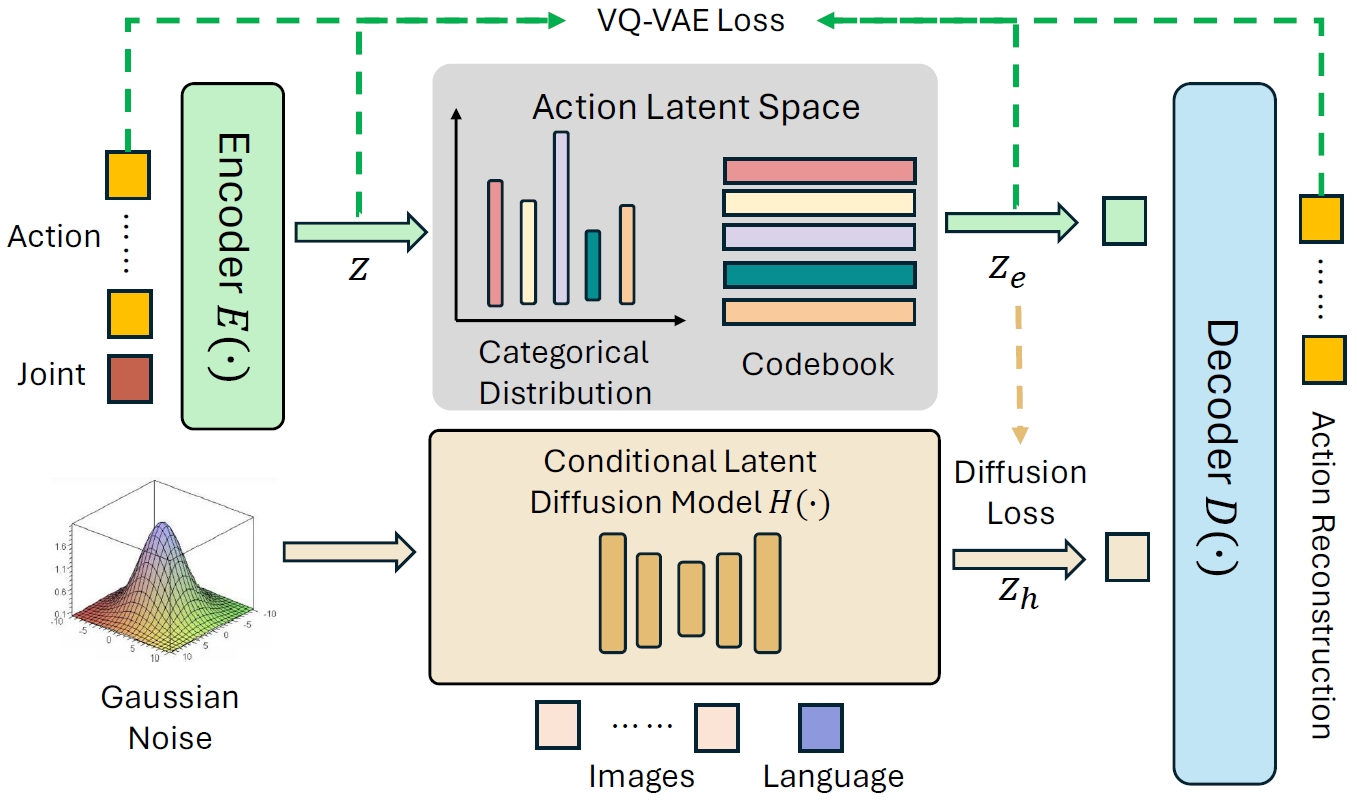
Discrete Policy: In the first training stage, as indicated by the green arrow, we train a VQ-VAE that maps actions into discrete latent space with an encoder and then reconstructs the actions based on the latent embeddings using a decoder. In the second training stage, as indicated by the brown arrow, we train a latent diffusion model that predicts task-specific latent embeddings to guide the decoder in predicting accurate actions.
Experiments
We ask the following key questions about the effectiveness of our algorithm: 1) Can Discrete Policy be effectively deployed to real-world scenarios? 2) Can Discrete Policy be scaled up to multiple complex tasks? 3) Can Discrete Policy effectively distinguish different behavioral modalities across multiple tasks? In order to answer these questions, we built a real-world robotic arm environment, designed a variety of manipulation tasks that contain rich skill requirements and long-horizon tasks, and finally conducted extensive experiments.
Task Description for Real-World Experiments

For the single-arm Franka experiments, we designed two multi-task evaluation protocols named Multi-Task 5 (MT-5) and Multi-Task 12 (MT-12).
MT-5 contains 5 tasks: 1) PlaceTennis. 2) OpenDrawer. 3) OpenBox. 4) StackBlock. 5) UprightMug.
MT-12 extends MT-5's task range to 12 tasks, including 3 long-horizon tasks, more varied scenarios, and more complex skill requirements such as flip, press, and pull.
The 12 tasks are: 1) PlaceTennis. 2) OpenDrawer. 3) OpenBox. 4) StackBlock. 5) UprightMug. 6) CloseDrawer. 7) PlaceCan. 8) ArrangeFlower. 9) CloseMicrowave. 10) InsertToast. 11) StoreToyCar. 12) DisposePaper.

For the bimanual UR5 robotic experiments, we designed 6 challenging tasks that require collaboration between two robotic arms.
The 6 tasks are: 1) TennisBallPack. 2) BreadTransfer. 3) StackBlock. 4) BreadDrawer. 5) SweepPaper-1. 6) SweepPaper-2.
Quantitative Comparison
Results on Single-arm Franka Robot.
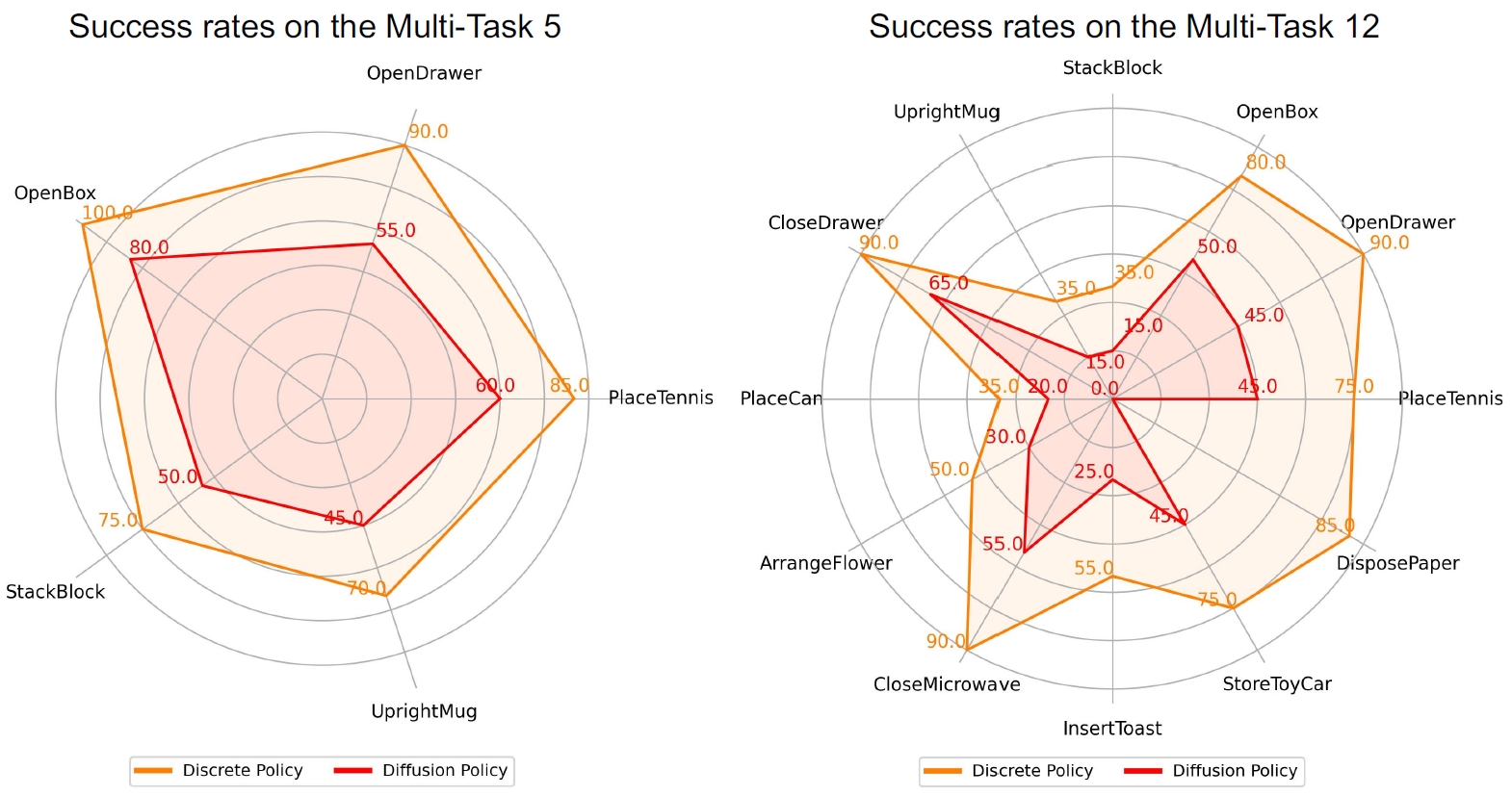
The figures on the left and right show the success rates on the MT-5 and MT-12, respectively.
| Method | PlaceTennis | OpenDrawer | OpenBox | StackBlock | UprightMug | Average |
|---|---|---|---|---|---|---|
| RT-1 | 25 | 30 | 30 | 10 | 15 | 22 |
| BeT | 45 | 30 | 65 | 30 | 15 | 37 |
| BESO | 40 | 30 | 55 | 25 | 15 | 33 |
| MDT | 50 | 35 | 55 | 20 | 25 | 37 |
| Octo* | 40 | 55 | 50 | 30 | 40 | 43 |
| OpenVLA* | 85 | 80 | 90 | 40 | 50 | 69 |
| MT-ACT | 80 | 80 | 100 | 55 | 45 | 59 |
| Diffusion Policy | 60 | 55 | 80 | 50 | 45 | 58 |
| Discrete Policy | 85 | 90 | 100 | 75 | 70 | 84 |
Results on Bimanual UR5 robot.
| Method | TennisBallPack | BreadTransfer | StackBlock | BreadDrawer | SweepPaper-1 | SweepPaper-2 | Average |
|---|---|---|---|---|---|---|---|
| BeT | 30 | 10 | 0 | 30 | 40 | 20 | 21.7 |
| MT-ACT | 70 | 40 | 10 | 70 | 80 | 60 | 55.0 |
| Diffusion Policy | 30 | 35 | 0 | 45 | 65 | 50 | 37.5 |
| Discrete Policy | 70 | 55 | 30 | 85 | 85 | 75 | 65.8 |
Visualization of Discrete Policy
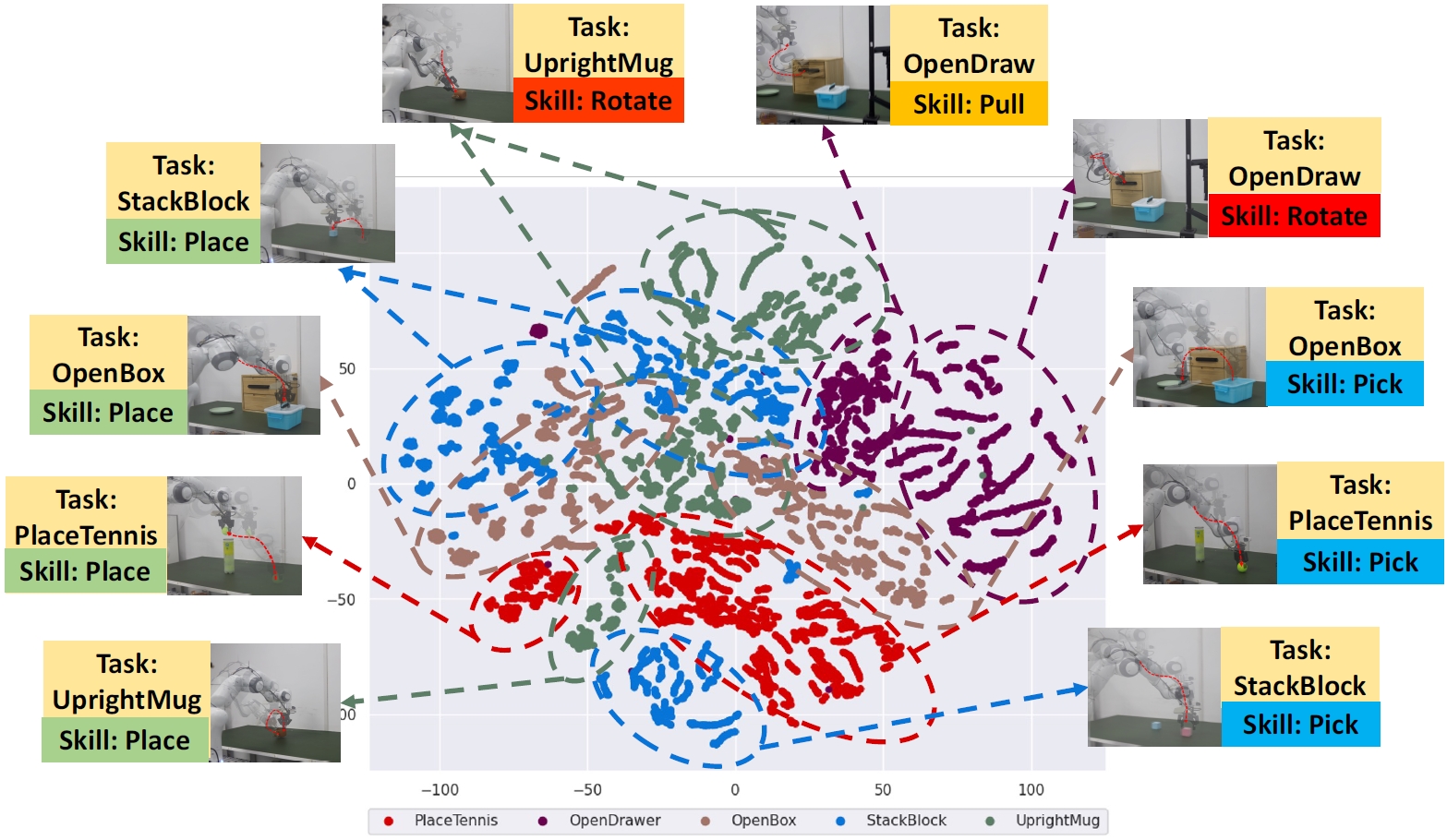
The t-SNE visualization of feature embeddings from Discrete Policy reveals that skills across different tasks cluster closely together. This pattern suggests that discrete latent spaces are capable of disentangling the complex, multimodal action distributions encountered in multi-task policy learning.
Qualitative Comparison
We qualitatively compare discrete policy with diffusion policy and show some cases where diffusion policy fails.
Discrete Policy (Ours)
Diffusion Policy
BibTeX
@article{wu2024discrete,
title={Discrete Policy: Learning Disentangled Action Space for Multi-Task Robotic Manipulation},
author={Wu, Kun and Zhu, Yichen and Li, Jinming and Wen, Junjie and Liu, Ning and Xu, Zhiyuan and Qiu, Qinru and Tang, Jian},
journal={arXiv preprint arXiv:2409.18707},
year={2024}
}